Motivation
Social media platforms have revolutionized how people interact with dance content, with TikTok as a prominent example. However, data collected from such sources often suffer from missing joints, occlusions, and noisy skeleton data, which traditional motion capture systems fail to handle efficiently. DanceFusion addresses these issues by reconstructing missing or noisy motion sequences while maintaining musical synchronization, generating realistic and engaging dance motions that can be applied to content creation, gaming, and virtual avatars.
Key Features
- Hierarchical Spatio-Temporal VAE for Motion Reconstruction: We introduce a hierarchical Transformer-based Variational Autoencoder (VAE) that integrates spatio-temporal encoding to effectively capture both spatial joint configurations and temporal movement dynamics. This integration enhances the model's ability to reconstruct incomplete and noisy skeleton data with high accuracy
- Integration of Diffusion Models for Audio-Driven Motion Generation: By incorporating diffusion models, DanceFusion iteratively refines motion sequences, significantly improving motion realism and ensuring precise synchronization with audio inputs.
- Advanced Masking Techniques: We develop sophisticated masking strategies to manage missing or unreliable joint data, allowing the model to prioritize and accurately reconstruct available information.
Methodology
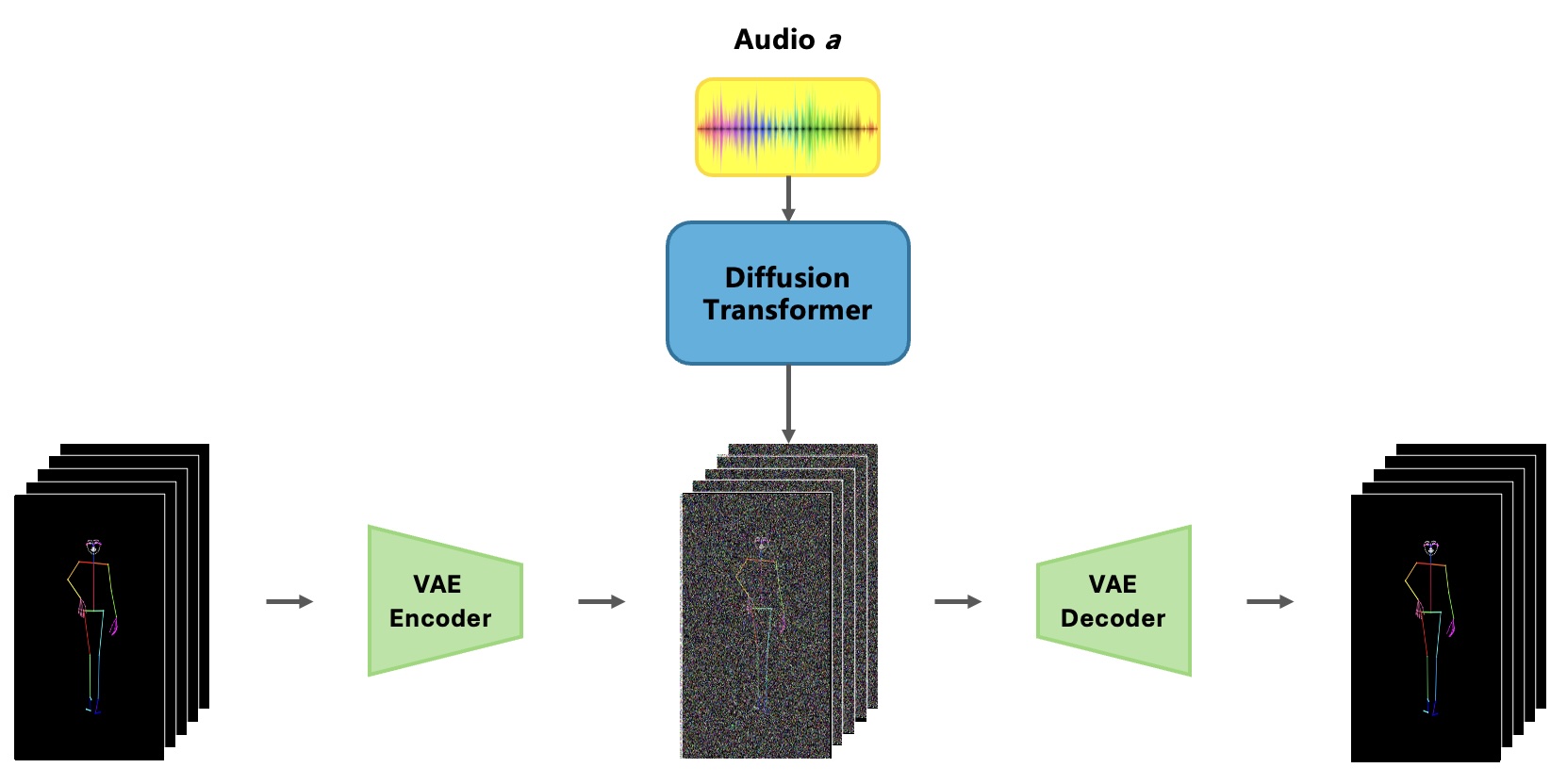
In this chapter, we present the DanceFusion framework, which integrates a hierarchical Spatio-Temporal Transformer-based Variational Autoencoder (VAE) with a diffusion model to achieve robust motion reconstruction and audio-driven dance motion generation. The input to the model is a sequence of skeleton joints extracted from TikTok dance videos, often containing missing or noisy data. The framework aims to refine these skeleton sequences through a series of denoising steps, ensuring that the generated or reconstructed motion is temporally consistent and aligned with accompanying audio.
1. Hierarchical Spatio-Temporal VAE Encoding
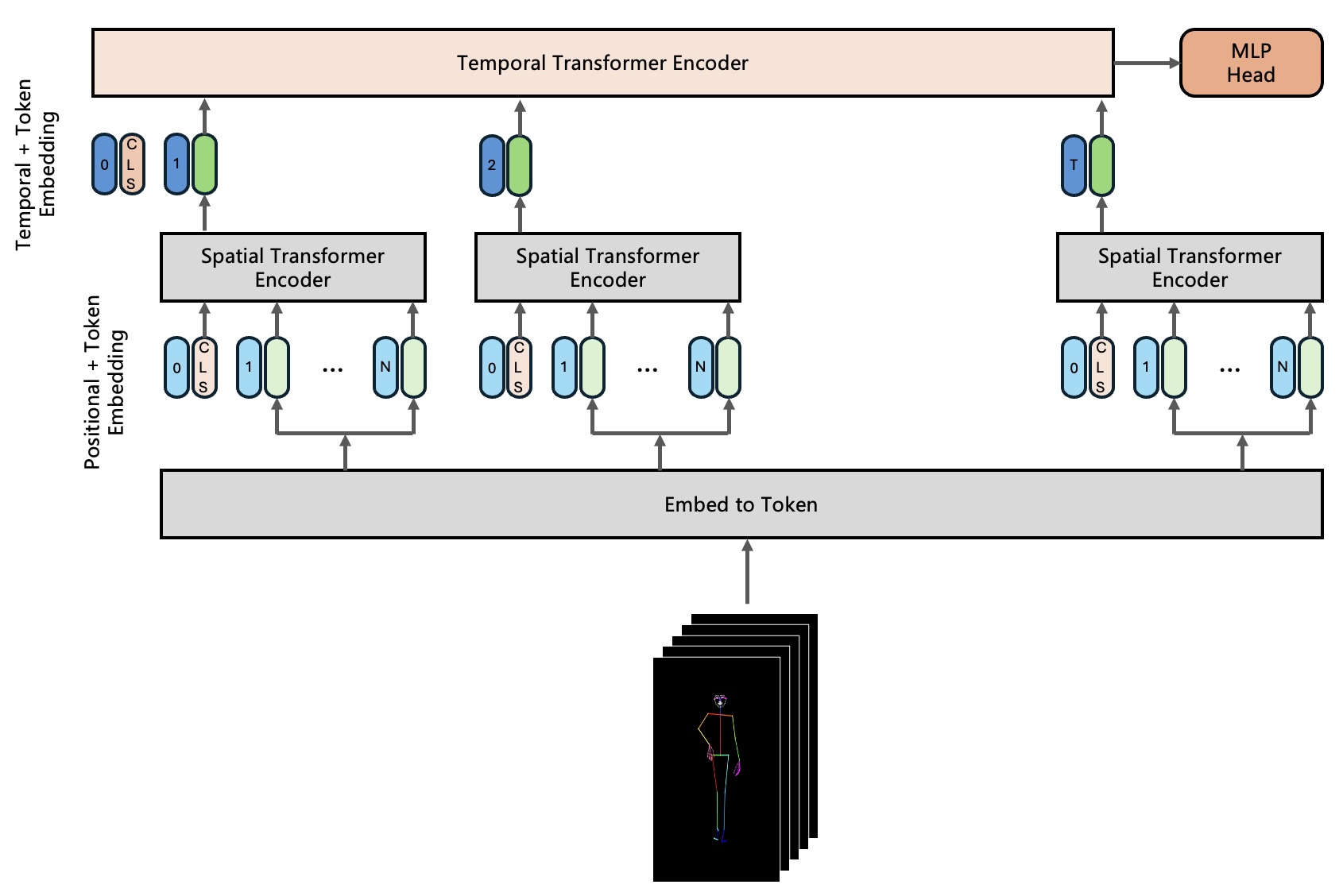
The DanceFusion framework introduces a hierarchical Transformer-based Variational Autoencoder (VAE) that integrates spatio-temporal encoding to capture the spatial and temporal information inherent in skeleton sequences. Unlike image-based models like ViViT, which processes grid patches from static images, we treat each skeleton joint as a token, and the sequence of joints over time forms a spatio-temporal grid. Each joint in the skeleton is encoded based on its spatial relationship with other joints, and the temporal sequence of these joint positions is fed into the Transformer for processing.
2. Diffusion Model for Audio-Driven Motion Generation
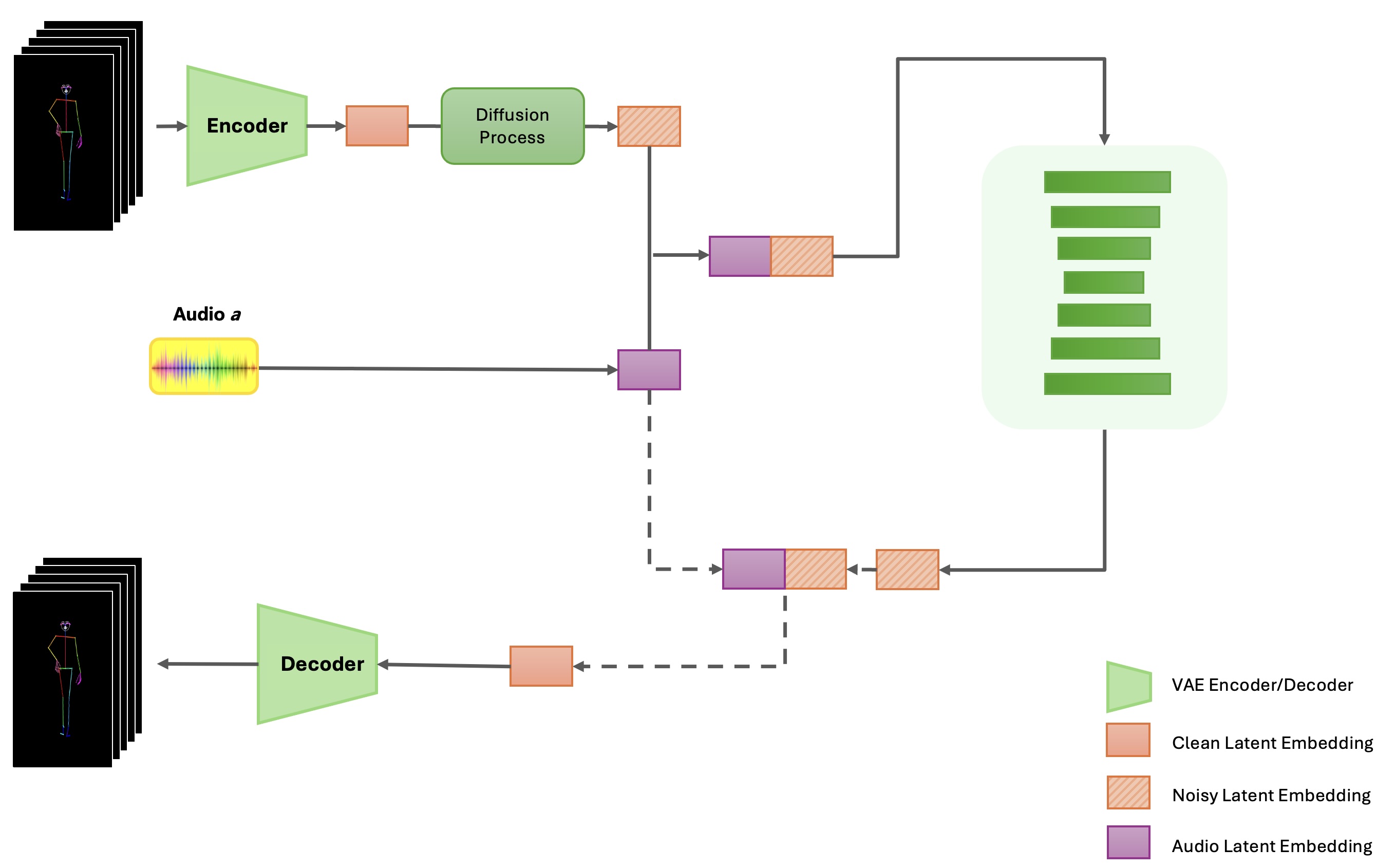
Diffusion models have gained prominence in the generation of complex data sequences, demonstrating exceptional ability in synthesizing realistic and contextually accurate motion sequences. In DanceFusion, we leverage diffusion models to refine skeleton sequences and synchronize dance movements with audio inputs, thus enhancing both the visual quality and the auditory alignment of generated dance sequences.
3. Handling Incomplete Skeleton Data
One of the major challenges in motion reconstruction is handling incomplete skeleton data, where certain joints may be missing due to occlusions or sensor noise. In the DanceFusion framework, this is addressed through a masking mechanism applied during the encoding phase. Each joint in the input sequence is either present or missing, and this information is captured in a binary mask. The mask prevents the model from considering missing joints during the spatial encoding process, ensuring that only reliable joints contribute to the final representation.
Experiment Results
Evaluation Metrics
- FID (Fréchet Inception Distance): Used to measure the quality of generated dance sequences by comparing their distribution to real dance motions.
- Diversity Score: Quantifies the variation and uniqueness of generated sequences to ensure that outputs are not repetitive.
Results Summary
- FID: DanceFusion demonstrates significantly lower FID scores compared to baseline models, indicating higher fidelity and realism in generated motions.
- Diversity: The generated motions exhibit high diversity, showing that the model can produce a wide range of dance styles and movements.